Databricks Core Concepts
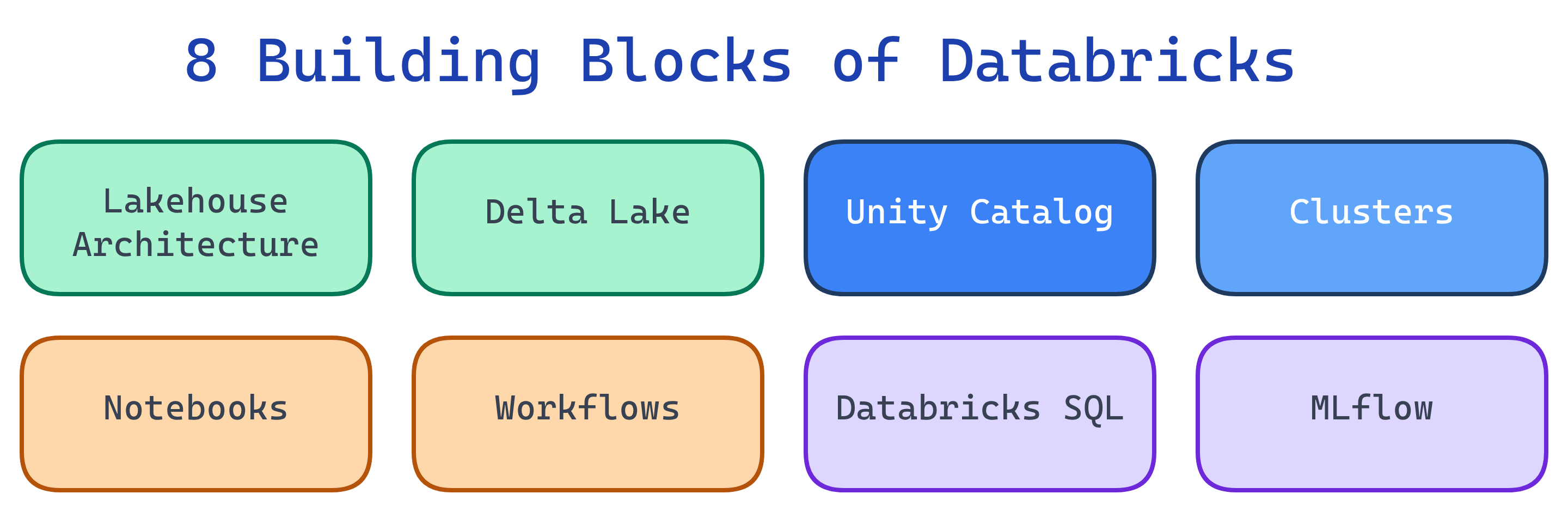
Databricks has 8 building blocks: Lakehouse architecture, Delta Lake storage, Unity Catalog governance, Clusters for compute, Notebooks for coding, Workflows for orchestration, Databricks SQL for BI, and MLflow for ML lifecycle. Master these and you understand the whole platform.
Explain Like I'm 12
Think of Databricks as a giant LEGO set for data. The Lakehouse is the base plate. Delta Lake is how you store your bricks neatly (not thrown in a pile). Unity Catalog is the instruction manual that says who can use which bricks. Clusters are the workers who snap bricks together. Notebooks are where you draw your designs. Workflows tell workers what order to build in. Databricks SQL lets business people ask questions about the finished model. And MLflow is the quality control team that tests if the model is good.
Cheat Sheet
| Concept | What It Is | Plain English |
|---|---|---|
| Lakehouse | Architecture combining lake + warehouse | One system for all data — no more copying between lake and warehouse |
| Delta Lake | Open storage layer with ACID transactions | Your data lake becomes reliable — no more corrupted or partial files |
| Unity Catalog | Unified governance for data and AI | One place to control who can see what, plus lineage and discovery |
| Cluster | Group of VMs that run your Spark jobs | The compute power — scales up when you need it, shuts down when you don't |
| Notebook | Interactive document with code + results | Like a Google Doc but for code — write SQL, Python, or Scala and see results inline |
| Workflow | Orchestrated sequence of tasks | Automate: "Run this notebook, then that one, every day at 6 AM" |
| Databricks SQL | Serverless SQL analytics engine | A fast SQL warehouse for BI tools — connect Power BI, Tableau, etc. |
| MLflow | ML experiment tracking and model registry | Track which model version works best, then deploy the winner |
1. Lakehouse Architecture
The lakehouse is the foundational idea behind Databricks. Instead of maintaining a data lake (raw files in cloud storage) AND a data warehouse (structured, expensive), you use one system that gives you both.
| Layer | What Lives Here |
|---|---|
| Bronze | Raw data exactly as ingested — no transformations |
| Silver | Cleaned, deduplicated, joined — conforming to schemas |
| Gold | Aggregated, business-ready — ready for dashboards and ML |
2. Delta Lake
Delta Lake is the storage format that makes the lakehouse possible. It's an open-source project that adds ACID transactions, schema enforcement, and time travel to Parquet files.
-- Create a Delta table
CREATE TABLE sales (
id BIGINT,
product STRING,
amount DECIMAL(10,2),
sold_at TIMESTAMP
) USING DELTA;
-- Time travel: query yesterday's version
SELECT * FROM sales VERSION AS OF 42;
-- Restore to a previous version
RESTORE TABLE sales TO VERSION AS OF 42;3. Unity Catalog
Unity Catalog is the governance layer. It provides a 3-level namespace: catalog.schema.table. You define access policies once, and they apply across all workspaces.
-- Grant read access to a schema
GRANT SELECT ON SCHEMA analytics.finance TO `[email protected]`;
-- View data lineage
-- (Available in the Catalog Explorer UI)4. Clusters
A cluster is a set of cloud VMs that run your Spark code. Databricks manages Spark for you — you just pick a size and go.
| Cluster Type | When to Use |
|---|---|
| All-Purpose | Interactive notebooks, development, ad-hoc analysis |
| Job Cluster | Automated workflows — spins up, runs the job, shuts down |
| SQL Warehouse | BI queries from Tableau, Power BI, or Databricks SQL |
5. Notebooks
Notebooks are your interactive workspace. Each cell can be Python, SQL, Scala, or R. Results render inline — tables, charts, and text.
# Python cell
df = spark.read.table("analytics.sales")
display(df.groupBy("product").sum("amount"))-- SQL cell (use %sql magic command in Python notebooks)
SELECT product, SUM(amount) as total
FROM analytics.sales
GROUP BY product
ORDER BY total DESC6. Workflows
Workflows let you orchestrate tasks: run notebooks, Python scripts, dbt models, or Spark JARs on a schedule or trigger. Each task gets its own job cluster (cost-efficient).
7. Databricks SQL
Databricks SQL is a serverless SQL engine optimized for BI workloads. It lets analysts query Delta tables with standard SQL, create dashboards, and connect BI tools.
| Feature | Details |
|---|---|
| SQL Editor | Write and run SQL queries in the browser |
| Dashboards | Build visualizations from query results |
| Alerts | Get notified when a query result crosses a threshold |
| BI Connectors | Partner Connect for Tableau, Power BI, Looker, etc. |
8. MLflow
MLflow is an open-source platform for the ML lifecycle. On Databricks, it's pre-installed and integrated with Unity Catalog for model governance.
import mlflow
with mlflow.start_run():
mlflow.log_param("learning_rate", 0.01)
mlflow.log_metric("rmse", 0.85)
mlflow.sklearn.log_model(model, "model")Test Yourself
Q: What are the three layers of the Medallion architecture?
Q: What's the difference between an all-purpose cluster and a job cluster?
Q: What namespace hierarchy does Unity Catalog use?
catalog.schema.table (three levels). For example: production.finance.invoices. You grant access at any level — catalog, schema, or individual table.Q: How does Delta Lake differ from plain Parquet?
Q: When would you use Databricks SQL instead of a notebook?