Scalability & Reliability
Scalability means handling more load. Reliability means staying up. Horizontal scaling adds more machines, vertical adds more power. Use replication for availability, sharding for scale, circuit breakers for resilience, and rate limiting for protection.
Explain Like I'm 12
Imagine you run a restaurant. Vertical scaling is making your kitchen bigger — more stoves, more counter space. It works, but eventually you run out of room. Horizontal scaling is opening more restaurants across town. Each one handles its own customers, and together they serve way more people.
Reliability is making sure that if one restaurant catches fire, the others keep running. You have backup plans, spare ingredients, and a manager who can step in if the head chef gets sick. The goal: customers always get served, no matter what goes wrong.
Scalability Overview
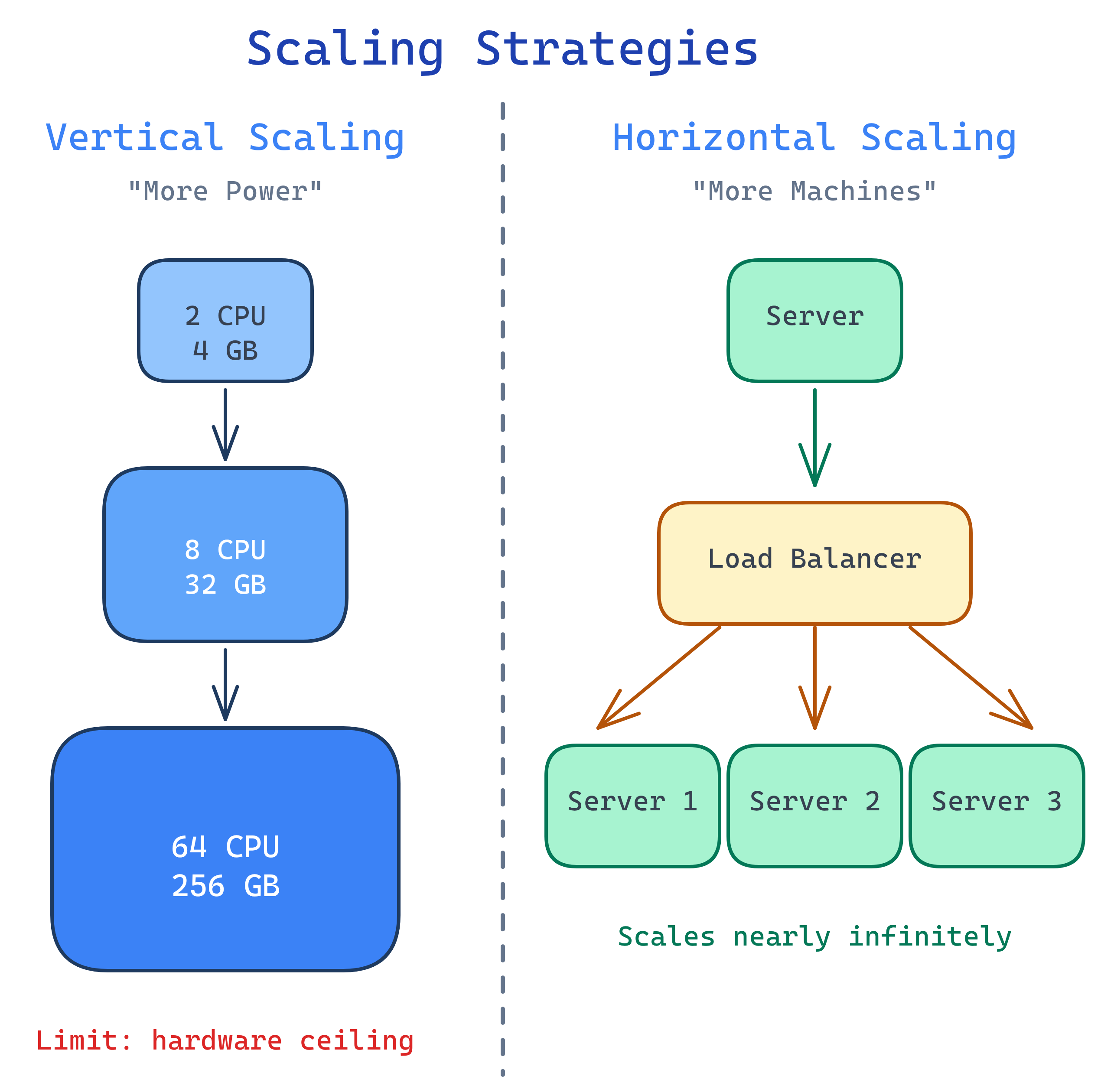
Vertical vs Horizontal Scaling
Every system eventually hits a traffic ceiling. The question is: do you make the box bigger, or add more boxes?
| Aspect | Vertical Scaling (Scale Up) | Horizontal Scaling (Scale Out) |
|---|---|---|
| What it does | Bigger CPU, more RAM, faster disks | More machines behind a load balancer |
| Cost curve | Exponential (high-end hardware is disproportionately expensive) | Linear (add commodity machines) |
| Limit | Hard ceiling (biggest machine available) | Virtually unlimited |
| Complexity | Low (same code, bigger box) | Higher (load balancing, distributed state, consistency) |
| Downtime | Often requires restart during upgrade | Zero-downtime (add/remove servers live) |
| Single point of failure | Yes (one machine) | No (if designed correctly) |
| Best for | Databases, small-medium traffic, quick wins | Web servers, microservices, high-traffic systems |
Stateless vs Stateful Services
Horizontal scaling only works well when your services are stateless. Here's why.
Stateless Services
The server doesn't remember anything between requests. Every request contains all the information needed to process it. Think of it like a cashier who doesn't recognize you — you show your receipt every time.
- Session data is stored externally (Redis, database, JWT token)
- Any server can handle any request — the load balancer picks freely
- Easy to scale: add more servers, remove failed ones, no data loss
- Example: REST API servers, serverless functions (AWS Lambda)
Stateful Services
The server remembers something about the client between requests. Like a bartender who knows your "usual."
- Sticky sessions required — the load balancer must route the same client to the same server
- Harder to scale: if that specific server goes down, the user's state is lost
- Example: WebSocket connections, in-memory session stores, game servers
Replication
Replication means keeping copies of your data on multiple machines. It's your first line of defense against data loss and your main tool for scaling reads.
Master-Slave (Primary-Replica)
One master handles all writes. Multiple replicas handle reads. The master pushes changes to replicas.
- Reads scale: add more replicas to handle more read traffic
- Writes don't scale: all writes still go to one master
- Failover: if the master dies, promote a replica to master (manual or automatic)
- Replication lag: replicas may be slightly behind the master (eventual consistency)
Master-Master (Multi-Primary)
Multiple nodes accept both reads and writes. Changes are replicated between them.
- Writes scale better: multiple nodes accept writes
- Conflict risk: two nodes may update the same row simultaneously — needs conflict resolution
- More complex: harder to set up and debug than master-slave
- Use case: multi-region deployments where you need low-latency writes in each region
Sync vs Async Replication
| Aspect | Synchronous | Asynchronous |
|---|---|---|
| How it works | Master waits for replica to confirm before acking the write | Master acks immediately, replica catches up later |
| Consistency | Strong (replica always up-to-date) | Eventual (replica may lag behind) |
| Latency | Higher (must wait for replica) | Lower (no waiting) |
| Risk | Write fails if replica is down | Data loss if master dies before replica catches up |
CAP Theorem
The CAP theorem says a distributed system can guarantee at most two of three properties:
| Property | What it means | Example |
|---|---|---|
| Consistency (C) | Every read returns the most recent write. All nodes see the same data at the same time. | Bank account balance (must be accurate) |
| Availability (A) | Every request gets a response (even if it might be stale). The system never refuses to answer. | Social media "like" count (ok if slightly stale) |
| Partition Tolerance (P) | The system keeps working even when network messages are lost or delayed between nodes. | Any multi-datacenter deployment |
CP vs AP in Practice
| Choose CP (Consistent) | Choose AP (Available) |
|---|---|
| Banking, financial transactions | Social media feeds, like counts |
| Inventory management (prevent overselling) | Product catalog (ok if slightly stale) |
| User authentication (must be accurate) | DNS resolution (cached is fine) |
| Examples: MongoDB (default), Redis Cluster, HBase | Examples: Cassandra, DynamoDB, CouchDB |
Reliability Patterns
A reliable system keeps working (maybe in a degraded state) even when things go wrong. Here are the patterns that make that happen.
Redundancy
Eliminate single points of failure. Every critical component should have at least one backup. Two load balancers (active-passive), multiple app servers, replicated databases, multi-AZ deployment.
Health Checks
The load balancer pings each server periodically. If a server stops responding, traffic is automatically routed away from it. Types: TCP checks (is the port open?), HTTP checks (does /health return 200?), deep checks (can the app reach the database?).
Circuit Breakers
Think of an electrical circuit breaker. If a downstream service starts failing, the circuit "opens" and requests fail fast instead of waiting and timing out. This prevents cascading failures.
- Closed: normal operation, requests pass through
- Open: service is down, fail immediately (return cached data or error)
- Half-open: after a cooldown, let a few requests through to test if the service recovered
Retry with Exponential Backoff
When a request fails, retry — but wait longer between each attempt: 1s, 2s, 4s, 8s... Add jitter (random variation) so thousands of clients don't all retry at the exact same moment (thundering herd).
Rate Limiting
Protect your service by limiting how many requests a client can make in a given time window. Common algorithms:
- Token bucket: a bucket fills with tokens at a fixed rate. Each request costs one token. When empty, requests are rejected. Allows bursts up to bucket size.
- Sliding window: count requests in a rolling time window. More accurate than fixed windows. Used by most API gateways.
- Fixed window: count requests per calendar interval (e.g., per minute). Simple but has edge cases at window boundaries.
Graceful Degradation
When part of the system is overloaded, serve a reduced experience instead of failing completely. Examples: show cached data instead of real-time, disable recommendations but keep search working, serve static pages when the API is down.
SLAs, SLOs, SLIs
How do you measure and promise reliability? Three related but different concepts.
| Term | What it is | Example |
|---|---|---|
| SLI (Service Level Indicator) | The actual metric you measure | 99.95% of requests returned in < 200ms |
| SLO (Service Level Objective) | Internal target for the SLI | We aim for 99.9% uptime |
| SLA (Service Level Agreement) | Contract with customers (with penalties) | "99.9% uptime or we credit your bill" |
The "Nines" of Availability
| Availability | Downtime / Year | Downtime / Month | Who targets this |
|---|---|---|---|
| 99% (two nines) | 3.65 days | 7.3 hours | Internal tools, batch jobs |
| 99.9% (three nines) | 8.77 hours | 43.8 minutes | Most SaaS products |
| 99.99% (four nines) | 52.6 minutes | 4.38 minutes | E-commerce, fintech |
| 99.999% (five nines) | 5.26 minutes | 26.3 seconds | Telecom, critical infrastructure |
Test Yourself
Q: You have a web app handling 1,000 requests/second. Traffic is expected to grow 10x in the next year. Would you scale vertically or horizontally? Why?
Q: What is the difference between replication and sharding? When do you use each?
Q: A social media app has both "bank transfer" and "like count" features. How would you apply the CAP theorem differently to each?
Q: Your service calls a downstream payment API that's been timing out. What reliability patterns would you apply?
Q: What does "five nines" availability mean, and why is going from 99.9% to 99.99% so much harder?
Interview Questions
Q: How would you design a system to handle a flash sale where traffic spikes 100x for 10 minutes?
Q: Explain consistent hashing and why it's preferred over simple modulo-based sharding.
hash(key) % N), adding or removing a server changes N, which reassigns almost every key to a different server — massive data movement. Consistent hashing places servers on a virtual ring. Each key maps to the next server clockwise. When you add a server, only the keys between the new server and its predecessor move (~1/N of the total data). This minimizes redistribution. Virtual nodes (multiple positions per server) improve balance. Used by Cassandra, DynamoDB, Memcached, and most CDNs.Q: You're designing a global e-commerce platform. How do you handle users in the US and Europe with low latency and compliance with GDPR?
Q: What is the difference between a load balancer and an API gateway? When would you use both?