What is Databricks?
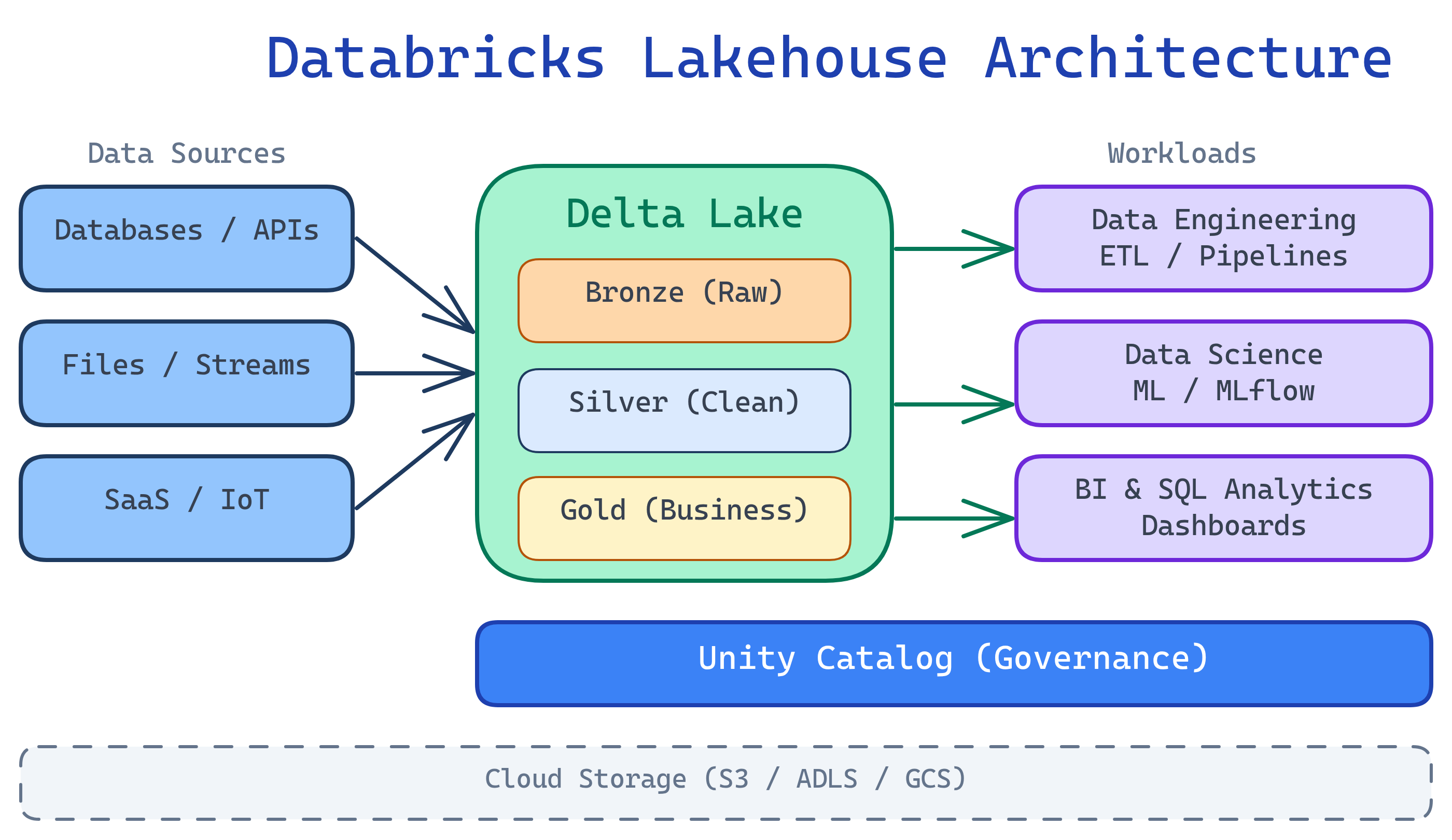
Databricks is a cloud-based unified analytics platform built on Apache Spark. It combines your data warehouse and data lake into a single lakehouse — so data engineers, data scientists, and analysts all work on the same data, in the same place, without copying it around.
The Big Picture
Before Databricks, companies had two separate systems: a data lake (cheap storage, messy data) and a data warehouse (expensive, clean, fast queries). Databricks merges them into a lakehouse — you get the low cost of a lake with the reliability and speed of a warehouse.
Explain Like I'm 12
Imagine your school has two libraries. One is a giant messy warehouse with every book ever — cheap but impossible to find anything. The other is a small, organized library with only the popular books — fast to search but expensive to maintain. Databricks is like combining both into one super-library where every book is organized AND you have access to everything. Plus, it gives you AI-powered librarians (notebooks) to help you find answers in seconds.
Who is Databricks For?
| Role | What You Do on Databricks |
|---|---|
| Data Engineer | Build ETL pipelines, manage Delta tables, orchestrate workflows |
| Data Scientist | Train ML models, run experiments with MLflow, use AutoML |
| Data Analyst | Write SQL queries, build dashboards, explore data in notebooks |
| Analytics Engineer | Transform data with dbt or SQL, manage data quality |
What You'll Learn
Key Capabilities
| Capability | What It Means |
|---|---|
| Delta Lake | ACID transactions on your data lake — no more corrupted files or partial writes |
| Unity Catalog | One place to govern access, lineage, and discovery across all your data |
| Workflows | Schedule and orchestrate notebooks, Python scripts, or dbt jobs |
| Databricks SQL | Serverless SQL warehouse for BI queries — connect Tableau, Power BI, etc. |
| MLflow | Track experiments, register models, deploy to production |
| AutoML | Automatically train and compare ML models with a few clicks |
| Notebooks | Interactive coding environment supporting Python, SQL, Scala, and R |
Databricks vs. Alternatives
| Feature | Databricks | Snowflake | BigQuery |
|---|---|---|---|
| Architecture | Lakehouse (open Delta Lake) | Cloud data warehouse | Serverless warehouse |
| Open formats | Delta, Parquet, Iceberg | Proprietary + Iceberg | Proprietary |
| ML / Data Science | Built-in (MLflow, AutoML) | Snowpark ML | Vertex AI integration |
| Real-time streaming | Structured Streaming | Snowpipe Streaming | Pub/Sub + Dataflow |
| SQL analytics | Databricks SQL (serverless) | Native SQL | Native SQL |
| Pricing model | DBU-based (per compute) | Credit-based (per compute) | Per-query + storage |
Test Yourself
Q: What problem does the "lakehouse" architecture solve?
Q: What is Delta Lake, and why does it matter?
Q: Name three roles that use Databricks and what each does.
Q: How is Databricks different from Snowflake?
Q: What is Unity Catalog?