What is The Tuva Project?
The Tuva Project is an open-source dbt framework that transforms raw healthcare claims and clinical data into analytics-ready datasets. It gives you a complete healthcare data pipeline — connectors, data quality, normalization, a core data model, and 13+ pre-built data marts for risk adjustment, quality measures, readmissions, and more.
Healthcare claims data is among the messiest data in any industry. A single patient encounter can generate dozens of claims across professional, facility, pharmacy, and ancillary categories, and the same event is coded differently across payers, providers, and years. The Tuva Project addresses this by standardizing claims and clinical data into a common data model with documented transformation logic. Before Tuva (or similar tools like OMOP), analytics teams commonly maintained proprietary transformation code that was difficult to audit or trust. The Tuva documentation explains the data model and mart structure.
FHIR (Fast Healthcare Interoperability Resources) is the API standard driving modern healthcare data exchange, mandated by CMS for payer interoperability. Understanding that FHIR Resources (Patient, Encounter, Claim, Observation) map roughly to the entities in a claims data model helps bridge the gap between raw source data and an analytics-ready schema. The HL7 FHIR R4 specification is the authoritative reference.
Healthcare data engineering is worth specializing in if you want to work on population health, value-based care, or clinical analytics. The domain has high barriers to entry (compliance, data access) but that same barrier creates durable career value. HIPAA compliance is a prerequisite for any work with identified data — start with the HHS HIPAA guidance.
The Big Picture
Tuva takes the hardest part of healthcare analytics — turning raw, messy data into something you can actually analyze — and gives you an open-source, battle-tested pipeline that handles it all.
Explain Like I'm 12
Imagine you have a huge messy box of hospital receipts, pharmacy slips, and doctor visit records — all in different formats. Tuva is like a magical sorting machine. You dump in the mess, it checks for errors, translates everything into the same language, organizes it into neat folders, and then automatically creates reports: Who's at risk? What's costing the most? Are patients getting the right care? It's built on dbt, so it's all SQL you can read and customize.
What is The Tuva Project?
The Tuva Project is an open-source healthcare data framework licensed under Apache 2.0, created by Tuva Health. At its core, it's a dbt package that runs inside your data warehouse — Snowflake, BigQuery, Redshift, or DuckDB.
You point it at your raw claims or clinical data, and it transforms that data into analytics-ready datasets. No custom pipelines, no proprietary tools, no black boxes. Just SQL you can read, test, and customize.
With 300+ GitHub stars and a growing community, Tuva is quickly becoming the standard open-source approach to healthcare data transformation.
Why Tuva Exists
Healthcare data is uniquely hard to work with. Here's why:
- Every payer and EHR formats data differently — there's no universal standard for how claims or clinical records are structured.
- Healthcare analytics requires deep domain expertise — risk adjustment, quality measures, and claims preprocessing involve complex business logic that takes years to learn.
- Teams rebuild the same pipelines over and over — every health plan, ACO, and analytics vendor writes similar SQL for similar problems.
Tuva codifies this domain expertise into reusable, tested, open-source SQL. Instead of every team reinventing the wheel, you inherit years of healthcare data engineering knowledge as a dbt package.
Who is it for?
Tuva is built for anyone working with healthcare data on a modern data stack:
- Healthcare data engineers building data pipelines for claims and clinical data
- Analytics engineers using dbt to model healthcare data
- BI developers creating dashboards for health plan performance
- Health plan analysts working on risk adjustment, quality measures, or cost analytics
- ACO data teams tracking quality metrics and shared savings
- Anyone building healthcare analytics on Snowflake, BigQuery, Redshift, or DuckDB
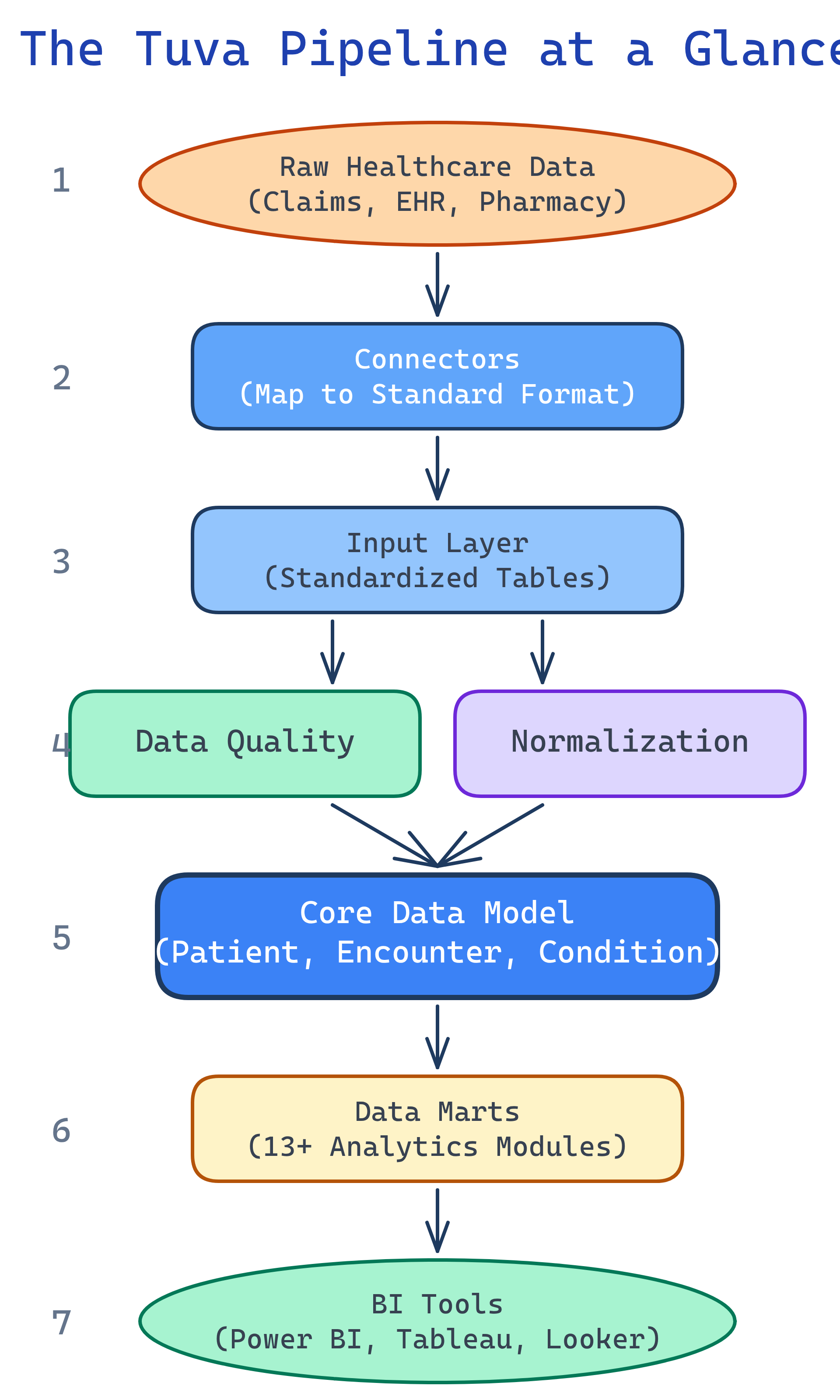
The Pipeline at a Glance
Tuva processes healthcare data through a 7-step pipeline. Each step builds on the previous one:
Key Features
Supported Warehouses
Tuva runs wherever your data lives. It supports the major cloud data warehouses and a local development option:
- Snowflake — Full production support
- BigQuery — Full production support
- Redshift — Full production support
- DuckDB — Local development and testing
Because Tuva is a dbt package, it compiles to native SQL for your warehouse. No additional infrastructure needed — it runs inside your existing dbt project.
What You'll Learn
This topic walks you through The Tuva Project from big picture to deep implementation details:
Test Yourself
What type of tool is Tuva (framework, SaaS, API)?
dbt build.What are the 7 stages of the Tuva pipeline?
What data warehouses does Tuva support?
Why is healthcare data particularly hard to work with?