What is MLOps?
MLOps (Machine Learning Operations) applies DevOps principles to ML systems. It automates the entire lifecycle — data preparation, model training, versioning, deployment, and monitoring — so models get to production reliably and stay healthy once they're there.
The Big Picture
MLOps is a continuous loop. Data flows in, models get trained and validated, the best model is deployed to production, and monitoring watches for drift — triggering retraining when the real world changes:
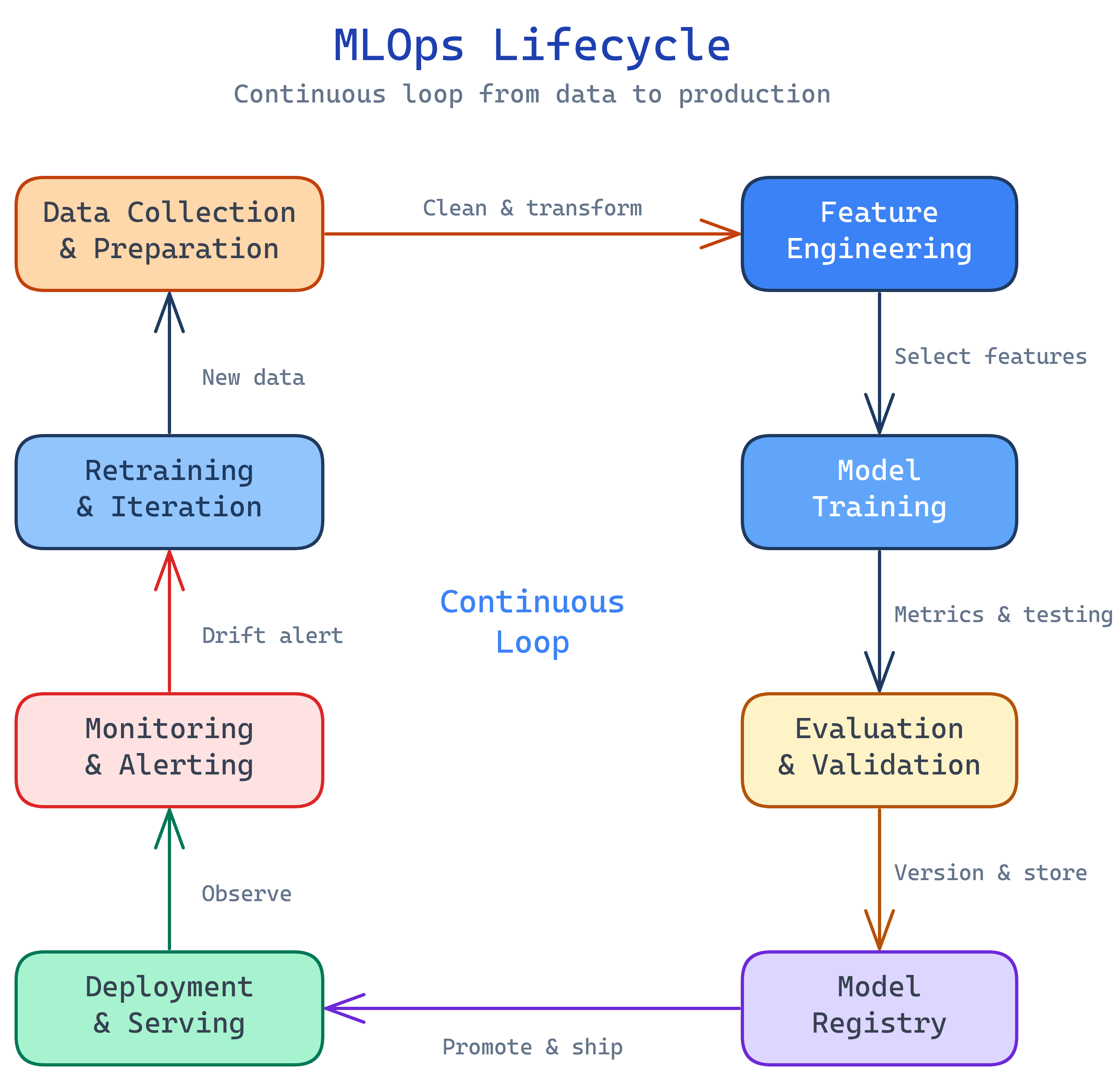
Explain Like I'm 12
Imagine you train a robot to sort your recycling. You show it hundreds of examples of cans, bottles, and paper. Eventually it gets pretty good. That's the fun part — training.
But now you need to put that robot in every recycling center in the city. You need to make sure it still works when someone throws in a new type of bottle it's never seen. You need alerts when it starts making mistakes. And you need a way to retrain it with new examples without shutting down all the recycling centers.
MLOps is the system that handles all of that. Training the robot is machine learning. Getting it into every recycling center, keeping it running, updating it, and monitoring its accuracy — that's MLOps.
What is MLOps?
MLOps is a set of practices, tools, and culture that brings DevOps principles to machine learning. The term combines "Machine Learning" and "Operations," and it emerged because getting ML models into production is hard — much harder than deploying traditional software.
Here's why ML is different from regular software:
- Code + Data + Model — Traditional software is just code. ML systems have three moving parts: the code that trains the model, the data it learns from, and the model artifact itself. All three need versioning.
- Models decay — Software doesn't get worse over time (bugs aside). ML models do. The world changes, data distributions shift, and yesterday's accurate model becomes today's wrong predictions. This is called model drift.
- Experiments are messy — Data scientists try hundreds of hyperparameter combinations, feature sets, and algorithms. Without tracking, nobody knows which experiment produced the model in production.
- The "last mile" problem — According to Gartner, only ~50% of ML projects ever make it to production. The gap between a notebook prototype and a production service is enormous.
MLOps closes that gap with automation, reproducibility, and monitoring.
Who is it for?
MLOps spans multiple roles. Data scientists use it to track experiments and reproduce results. ML engineers build the pipelines that automate training and deployment. Data engineers manage the feature pipelines that feed models. Platform engineers build the infrastructure (Kubernetes clusters, GPU nodes, model serving). And DevOps/SRE teams monitor model health in production alongside traditional services.
If your team trains ML models and needs them to work reliably in production, MLOps is for you.
What can you do with MLOps?
- Automate model training — trigger retraining pipelines when new data arrives or model performance drops
- Version everything — track code, data, models, and experiments so any result is reproducible
- Deploy models as services — serve predictions via REST APIs, batch jobs, or edge devices with blue-green and canary rollouts
- Monitor model health — track prediction accuracy, data drift, feature drift, and latency in real time
- Feature stores — centralize feature engineering so teams reuse features across models instead of reinventing them
- Governance and compliance — audit trails, model cards, bias detection, and approval workflows for regulated industries
Key Tools in the MLOps Ecosystem
The MLOps toolchain is growing fast. You don't need all of these, but you'll encounter them:
What you'll learn
This topic covers core concepts plus deep dives. Each one builds on the last:
Test Yourself
What makes deploying ML models harder than deploying traditional software?
What is model drift, and why does it matter?
Name three key MLOps practices that don't exist in traditional DevOps.
What percentage of ML projects reportedly make it to production, and what is the main blocker?