Agent Architectures & Patterns
Agent architectures determine how an agent reasons and acts. The simplest is ReAct (reason + act in a loop). More advanced patterns include Chain-of-Thought (step-by-step reasoning), Tree-of-Thought (explore multiple reasoning paths), Reflexion (self-critique and retry), and Plan-and-Execute (create a plan, then follow it). Choose based on task complexity and reliability requirements.
Explain Like I'm 12
Think of these architectures like different ways to solve a maze. ReAct is like walking through the maze one step at a time — look around, pick a direction, walk, repeat. Chain-of-Thought is like talking through your logic out loud: "If I go left, I hit a wall, so I'll go right." Tree-of-Thought is like sending clones of yourself down every path and picking the clone that gets furthest. Reflexion is like hitting a dead end, backing up, and saying "okay, what did I do wrong?" And Plan-and-Execute is like studying the maze from above first, drawing a route on paper, then following your map.
Architecture Comparison
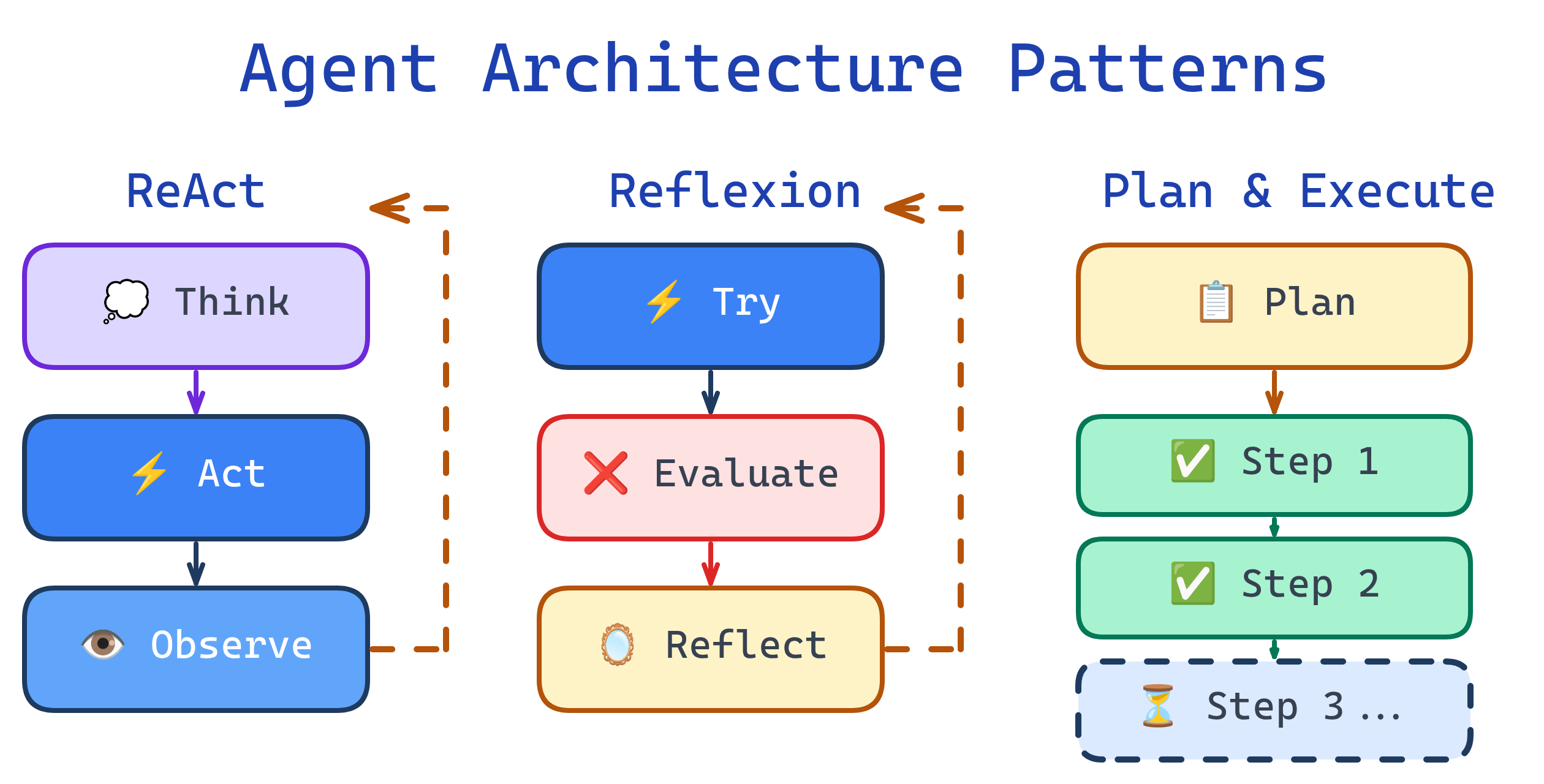
ReAct: Reasoning + Acting
ReAct (Reasoning and Acting) is the most common agent architecture. The agent alternates between thinking (generating reasoning traces) and acting (calling tools). It's simple, effective, and the foundation for most production agents.
# ReAct pattern: Thought → Action → Observation loop
system_prompt = """You are a helpful agent. For each step:
1. Thought: Reason about what to do next
2. Action: Call a tool if needed
3. Observation: Review the result
Repeat until the task is complete."""
# The LLM naturally generates this pattern:
# Thought: I need to find the bug. Let me read the auth module.
# Action: read_file(path="src/auth.py")
# Observation: [file contents...]
# Thought: I see the issue — the token expiry check is using < instead of <=
# Action: edit_file(path="src/auth.py", ...)| Pros | Cons |
|---|---|
| Simple to implement | Can get stuck in loops |
| Works with any LLM | No backtracking — can't undo bad decisions |
| Easy to debug (visible reasoning) | Greedy — takes the first "good enough" action |
| Low overhead per step | No global planning — purely reactive |
Chain-of-Thought (CoT)
Chain-of-Thought prompting makes the LLM show its reasoning step by step before reaching a conclusion. It's not an agent architecture per se, but it's a critical technique within agent architectures to improve reasoning quality.
# Chain-of-Thought: Force step-by-step reasoning
prompt = """Analyze this error and determine the root cause.
Think step by step:
1. What does the error message say?
2. What code path triggered it?
3. What are the possible causes?
4. Which cause is most likely given the context?
5. What's the fix?
Error: TypeError: Cannot read property 'id' of undefined at line 42 of users.js"""
# The LLM reasons through each step explicitly,
# leading to better answers than "just fix it"Tree-of-Thought (ToT)
Tree-of-Thought extends CoT by exploring multiple reasoning paths in parallel and selecting the best one. Instead of committing to the first chain of reasoning, the agent generates several candidates, evaluates them, and prunes bad branches.
# Tree-of-Thought: Explore multiple approaches
def tree_of_thought(problem, num_branches=3):
# Generate multiple candidate approaches
candidates = []
for i in range(num_branches):
approach = llm.generate(
f"Propose approach #{i+1} to solve: {problem}"
)
candidates.append(approach)
# Evaluate each approach
scores = []
for approach in candidates:
score = llm.generate(
f"Rate this approach 1-10 for correctness and efficiency: {approach}"
)
scores.append(score)
# Pick the best and execute
best = candidates[scores.index(max(scores))]
return agent_execute(best)Reflexion: Self-Critique and Retry
Reflexion adds a self-evaluation step after each attempt. If the agent fails or produces poor results, it reflects on what went wrong, generates a critique, and retries with the insight. This creates a learning loop within a single task.
# Reflexion: Try → Evaluate → Reflect → Retry
def reflexion_loop(task, max_attempts=3):
reflections = []
for attempt in range(max_attempts):
# Attempt the task (with past reflections as context)
result = agent_execute(task, past_reflections=reflections)
# Evaluate the result
evaluation = llm.generate(
f"Did this succeed? What went wrong?\n"
f"Task: {task}\nResult: {result}"
)
if evaluation.success:
return result
# Reflect and store the lesson
reflection = llm.generate(
f"What should I do differently next time?\n"
f"Failed attempt: {result}\nEvaluation: {evaluation}"
)
reflections.append(reflection)
return "Failed after max attempts"Plan-and-Execute
Plan-and-Execute separates planning from execution into two distinct phases. A planner agent creates a high-level plan, then an executor agent follows the plan step by step. The planner can be re-invoked if the plan needs adjustment.
# Plan-and-Execute: Two-phase architecture
def plan_and_execute(goal):
# Phase 1: Create the plan
plan = planner_llm.generate(
f"Create a step-by-step plan to accomplish: {goal}\n"
f"Output as a numbered list. Each step should be actionable."
)
results = []
for step in plan.steps:
# Phase 2: Execute each step
result = executor_agent.run(step)
results.append(result)
# Re-plan if needed
if result.needs_replanning:
remaining = plan.steps[plan.steps.index(step)+1:]
plan = planner_llm.generate(
f"Original plan: {plan}\n"
f"Completed: {results}\n"
f"Problem: {result.error}\n"
f"Revise remaining steps: {remaining}"
)
return resultsChoosing the Right Architecture
| Architecture | Best For | Complexity | Cost |
|---|---|---|---|
| ReAct | Most tasks, simple tool use | Low | Low |
| CoT + ReAct | Tasks requiring careful reasoning | Low | Low-Medium |
| Reflexion | Coding, writing, tasks with clear success criteria | Medium | Medium |
| Plan-and-Execute | Complex multi-step projects | Medium | Medium |
| Tree-of-Thought | High-stakes decisions, research | High | High |
Test Yourself
What does ReAct stand for and how does it work?
When would you choose Tree-of-Thought over ReAct?
How does Reflexion improve agent performance?
What's the main advantage of Plan-and-Execute over ReAct?
Why does Chain-of-Thought prompting improve LLM reasoning?
Interview Questions
You're building an agent that writes and debugs code. Which architecture would you choose and why?
How would you prevent a ReAct agent from getting stuck in an infinite loop?
Compare the cost tradeoffs between ReAct and Tree-of-Thought for a production system.